

No livro Castelo de Mentiras, eu e Rodrigo de Toledo abordamos as mentiras tradicionais na gestão de portfólio de projetos e produtos. Todavia há outras mentiras que não tocamos naquele texto. Muitas delas acontecem no dia a dia, enquanto trabalhamos em nossos times / organizações. Uma bem comum é a ideia de que precisamos sempre manter 100% de ocupação das pessoas.
Pessoas “paradas” devem ser evitadas a todo custo? Quando temos um especialista mais caro no time ouvimos gestores falando: “não posso mantê-lo parado. Sabe quanto ele custa?”. “Adiantam” trabalho porque essa pessoa não pode ficar parada. A situação muitas vezes é ainda pior. Quando times ou até mesmo a organização inteira está trabalhando em algo irrelevante apenas para manter as pessoas ocupadas.
Falácia: A alta ocupação das pessoas melhora a performance do time!
Recomendo a leitura do artigo de Don Reinertsen e Stefan Thomke: os seis mitos de desenvolvimento de produtos (em inglês). O primeiro mito, segundo os autores, uma falácia: “a alta ocupação das pessoas melhorará a performance do desenvolvimento de produto”. Grande mentira, piorará. Eles apresentam o seguinte gráfico:
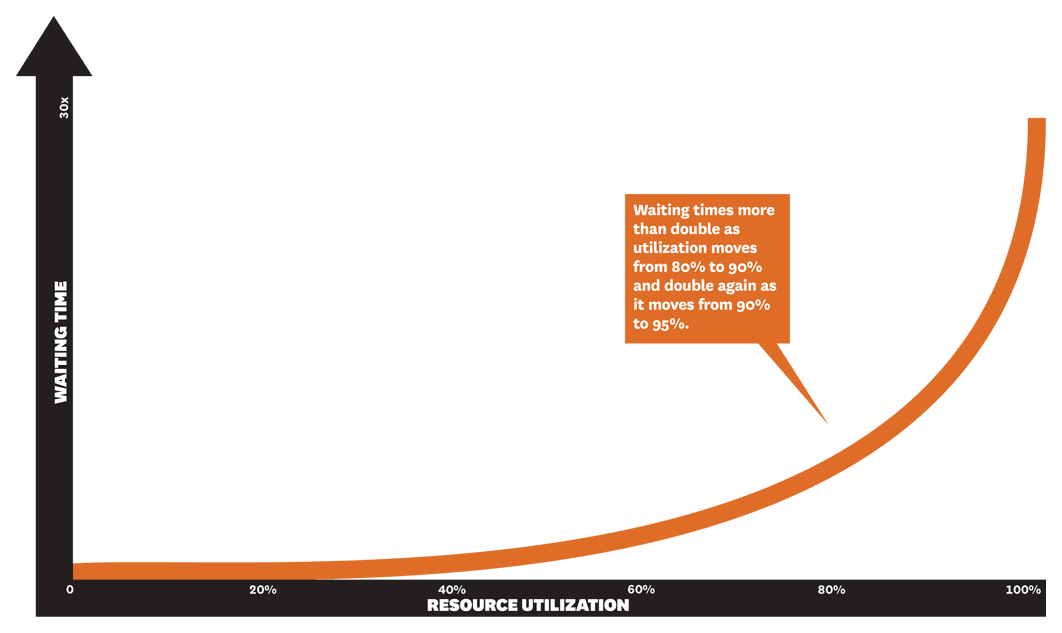
A leitura do gráfico disponível no artigo original é a seguinte: No eixo X, temos a utilização de pessoas (sim, eles chamaram de recursos). No eixo Y temos o tempo de espera. No estudo eles descobriram que o tempo de espera para um novo item entrar no fluxo dobra quando a ocupação do time vai de 60% para 80%. Dobra mais uma vez quando vai de 90% para 95% de ocupação. Em outras palavras, quanto mais as pessoas estão ocupadas, mais tempo os itens de trabalho ficarão aguardando essas pessoas ficarem disponíveis para dar continuidade ao item no fluxo.
Imagine a seguinte situação: seu time está todo ocupado, todos fazendo alguma coisa. Seu Product Owner precisa fazer um refinamento. Quem está disponível? Ninguém. Vai para a fila de espera e lá ficará.
Outra situação, um dos desenvolvedores precisa da ajuda de um dos avaliadores, infelizmente esses estão 100% ocupados, o desenvolvedor não consegue prosseguir com o item e sinaliza um bloqueio e pega o próximo item. Uma bela manhã, algumas semanas após o pedido de ajuda, finalmente uma das avaliadoras está disponível e resolve ajudar o desenvolvedor. Infelizmente, esse não ficou esperando e está trabalhando em outro item (de menor valor) e agora ele não tem tempo para falar com a avaliadora. Vai para a fila, a fila da fila e a fila da fila da fila. Já deu para entender o problema da alta ocupação.
Se essa ocupação acontece com times distintos que dependem um do outro a situação é ainda pior. Algo que é prioridade máxima de um time pode representar a prioridade 734 do outro. Não é incomum ver esse tipo de sofrimento em uma empresa.
O que fazer?
Visibilidade, o passo inicial para entender ocupação.
Primeiro, como você já sabe, visibilidade e transparência. Problemas que não são vistos, não podem ser tratados.
Coloque tudo em um quadro que mapeie o seu fluxo de trabalho para ter um vislumbre do que realmente está acontecendo: quais as etapas, quanto trabalho, upstream, downstream, quem está fazendo o que, capacidade etc.

Visualizar o problema é muito mais eficaz do que sair correndo feito um desesperado tentando responder algo que pode sequer existir. Não de soluções certas para os problemas errados.

Gerir filas mais que reduzir variabilidade
Faça a gestão das filas. Muitas pessoas acreditam que devemos reduzir a variabilidade, porém a variabilidade é inerente ao trabalho do conhecimento. Se você cria software, quantas vezes você criou dois softwares iguais? Quantas campanhas de marketing você fez exatamente iguais? Advogado, quantas defesas você fez que foram iguaizinhas?
Veja, não estou falando para você partir para a loucura total, não quero que meus times saiam inventando moda e fazendo tudo de qualquer jeito. Naquilo que merece padrão, padrão.
Vou dar um exemplo na minha área de desenvolvimento de software. Nós utilizamos Java com banco de dados Oracle. Os desenvolvedores podem começar a programar em Python com banco MySQL? Não. Sei que Python é legal e MySQL também é bacana. Todavia somos poucas pessoas e temos dezenas de aplicações em funcionamento. Se cada desenvolvedor resolver utilizar sua linguagem de programação, banco de dados ou paradigma favorito, virará um caos.
Padronizamos linguagem, banco de dados, frameworks (tem uns legados aqui também) e ferramentas. Agora, como as pessoas implementam os softwares e quais problemas eles resolvem, isso é “impadronizável” e, consequentemente, introduz variabilidade no nosso fluxo de trabalho. Logo, o que fazemos é gerir as filas de demandas e suas prioridades.
Lei de Little: Reduza a quantidade de trabalho em paralelo
Em 1954, o matemático John Little propôs o seguinte teorema: L = λ x W
L é o número médio de permanência de clientes em um sistema estacionário.
λ Aqui temos uma certa disputa. John Little afirma que é a taxa média efetiva de itens que chegam no sistema (taxa de chegada). Ele assume que a saída acontece na mesma proporção que a entrada, pois o sistema estaria em um estado estacionário. Veja neste artigo acadêmico. Já Don Reinertsen coloca como a média efetiva de itens processados pelo sistema (taxa de entrega, muitas vezes chamada de vazão ou em inglês throughput). Ver o livro The Principles of Product Development Flow, pp 73,74. Acredito que a solução de Reinertsen seja interessante, pois para trabalho do conhecimento a vazão de entrada nem sempre será igual à vazão de saída e o sistema pode não estar em um estado estacionário.
W é o tempo médio que um cliente gasta no sistema.
Parece complicado, mas podemos trazer um exemplo. Imagine que seu time recebe em média 2 novas demandas por dia. Digamos também que o seu Customer Lead Time, tempo desde o recebimento da demanda até a entrega para o cliente, seja em média, 7 dias. Temos então λ = 2 e W = 7. Usando o teorema teremos:
L = λ x W
L = 2 x 7
L = 14.
Em outras palavras, se olharmos para o quadro do seu time, veremos, em média, 14 itens por dia. “Kambanizando”, podemos dizer que o WIP = 14 itens. Perceba também que se utilizarmos o λ com a definição do Don Reinertsen, a conclusão seria a mesma.
Agora, como toda fórmula matemática, podemos fazer algumas trocas. Concordam que se L = λ x W, logo podemos ficar também que W = L ÷ λ

Agora vamos trocar essas variáveis com a nomenclatura que estamos mais acostumados no Kanban
L = WIP
W = Lead Time
λ = vazão (utilizando a solução de Don Reinertsen).
Temos agora:
W = L ÷ λ
Lead Time = WIP ÷ vazão
Nós queremos melhorar nossa performance, logo, reduzir nosso Lead Time. Como escrevi anteriormente, a vazão ou taxa de entrega não muda com muita facilidade, ela tende a se tornar quase constante ao longo do tempo. Se isso acontece e quero diminuir o Lead Time, minha única opção é reduzir o WIP. Vamos ver.
Um time que tem 14 itens andando em paralelo e a vazão é de 2 itens por dia.
W = L ÷ λ
Lead Time = WIP ÷ vazão
Lead time = 14 ÷ 2 / dia
Lead time = 7 dias
Se reduzirmos a quantidade de trabalho em paralelo de 14 para 10.
W = L ÷ λ
Lead Time = WIP ÷ taxa de chegada
Lead time = 10 ÷ 2 / dia
Lead time = 5 dias
Ou seja, quanto menos coisas fazemos em paralelo, mais rápido fazemos cada coisa.
Cuidado ao utilizar a Lei de Little
Objetivo da Lei de Little
A Lei de Little é boa para comprovarmos algo que podemos concluir empiricamente. Se estou lendo 1 livro e me dedico a ele, rapidamente terminarei de lê-lo. Agora, se estou lendo 5 livros simultaneamente, demorarei mais tempo para terminar o primeiro livro. Ficamos deslumbrados com a razão matemática que podemos perder o foco do motivo da existência dela: estimar o processamento de filas.
Na prática, aumento de WIP impacta negativamente a vazão
Você pode olhar para o exemplo que demos acima e dizer: Mas se a vazão continua sendo 2 itens por dias, que diferença faz se aumentarmos ou diminuirmos o Lead Time? Bem, a vida não é tão simplificada assim. Se você empurrar muita coisa para dentro do fluxo, fatalmente isso causará algum impacto negativo na vazão.
Cuidado com as médias
Além disso, a Lei de Little é baseada em relações de médias. Qualquer conta que você faça entre médias resulta em uma média. Logo, você não deverá utilizá-lo para trazer previsibilidade da entrega de itens.
Utilidade da Lei de Little
Sonya Siderova resume muito bem a utilidade: “A Lei de Little foi desenvolvida especificamente para usar dados já coletados como base para avaliar a estabilidade de um fluxo de trabalho de entrega.”. Você olha para o seu histórico e avalia se você tem um sistema estável e, acrescentaria, saudável, capaz de atender à demanda necessária sem sobrecarrega.
Siderova complementa: “A verdade é que a equação em si não é tão importante”. Ela nos traz à consciência um problema comum em diversas organizações. Se continuarmos aumentando a quantidade de itens de trabalho dentro de um sistema, tudo o que conseguiremos será nos tornar cada vez menos eficientes.
Conclusão
Espero ter ajudado a desmistificar a ideia de que precisamos de pessoas ocupadas. Não precisamos. Mesmo porque se só tivermos pessoas ocupadas não teremos entregas e sem entregas não geraremos resultado.
Quer aprender mais sobre essa questão e muito mais, que tal um dos nossos treinamentos de Kanban System Design da K21. Vamos, te encontro lá!
Pronto pra dar o próximo passo?
Conheça os cursos da K21 e leve essas ideias pra prática com quem vive agilidade todo dia.
Ver cursos K21

